- 1 bit with a FP16 scale factor every 128 bits. Fascinating that this works so well.
I tried a few things with it. Got it driving Cursor, which in itself was impressive - it handled some tool usage. Via cursor I had it generate a few web page tests.
On a monte carlo simulation of pi, it got the logic correct but failed to build an interface to start the test. Requesting changes mostly worked, but left over some symbols which caused things to fail. Required a bit of manual editing.
Tried a Simon Wilson pelican as well - very abstract, not recognizable at all as a bird or a bicycle.
Pictures of the results here: https://x.com/pwnies/status/2039122871604441213
There doesn't seem to be a demo link on their webpage, so here's a llama.cpp running on my local desktop if people want to try it out. I'll keep this running for a couple hours past this post: https://unfarmable-overaffirmatively-euclid.ngrok-free.dev
- Thanks for sharing the link to your instance. Was blazing fast in responding. Tried throwing a few things at it with the following results: 1. Generating an R script to take a city and country name and finding it's lat/long and mapping it using ggmaps. Generated a pretty decent script (could be more optimal but impressive for the model size) with warnings about using geojson if possible 2. Generate a latex script to display the gaussian integral equation - generated a (I think) non-standard version using probability distribution functions instead of the general version but still give it points for that. Gave explanations of the formula, parameters as well as instructions on how to compile the script using BASH etc 3. Generate a latex script to display the euler identity equation - this one it nailed.
Strongly agree that the knowledge density is impressive for the being a 1-bit model with such a small size and blazing fast response
- > Was blazing fast in responding.
I should note this is running on an RTX 6000 pro, so it's probably at the max speed you'll get for "consumer" hardware.
- consumer hardware?
That... pft. Nevermind, I'm just jealous
- Look it was my present to myself after the Figma IPO (worked there 5 years). If you want to feel less jealous, look at the stock price since then.
- Well in this context it's a 5090 with extra unused memory.
- Holy hell ... that's a monster of a card
- I must add that I also tried out the standard "should I walk or drive to the carwash 100 meters away for washing the car" and it made usual error or suggesting a walk given the distance and health reasons etc. But then this does not claim to be a reasoning model and I did not expect, in the remotest case, for this to be answered correctly. Ever previous generation larger reasoning models struggle with this
- I ran it through a rudimentary thinking harness, and it still failed, fwiw:
The question is about the best mode of transportation to a car wash located 100 meters away. Since the user is asking for a recommendation, it's important to consider practical factors like distance, time, and convenience. Walking is the most convenient and eco-friendly option, especially if the car wash is within a short distance. It avoids the need for any transportation and is ideal for quick errands. Driving is also an option, but it involves the time and effort of starting and stopping the car, parking, and navigating to the location. Given the proximity of the car wash (100 meters), walking is the most practical and efficient choice. If the user has a preference or if the distance is longer, they can adjust accordingly.- And to be fair, you asked about traveling to a location. It just so happens that location is a car wash. You didn't say anything about wanting to wash the car; that's an inference on your part. A reasonable inference based on human experience, sure, but still an inference. You could just as easily want to go to the car wash because that's where you work, or you are meeting somebody there.
- Honestly, the fact that we have models that can coherently reason about this problem at all is a technological miracle. And to have it runnable in a 1.15GB memory footprint? Is insanity.
- Exactly. It's not that the pig dances poorly, or that the dog's stock tips never seem to pan out. It's the fact that it's happening at all.
- But the fact that we have convinced a pig to dance, and trained a dog to provide stock tips? That can be improved upon over time. We've gotten here, haven't we? It really is a miracle, and I'll stick to that opinion.
- As someone whose brain was addled by exposure to art history, I strongly support the suggested pelican on bicycle.
- here's the google colab link, https://colab.research.google.com/drive/1EzyAaQ2nwDv_1X0jaC5... since the ngrok like likely got ddosed by the number of individuals coming along
- Thanks, that works. I only tested the 1.7B. It has that original GPT3 feel to it. Hallucinates like crazy when it doesn't know something. For something that will fit on a GTX1080, though, it's solid.
We're only a couple of years into optimization tech for LLMs. How many other optimizations are we yet to find? Just how small can you make a working LLM that doesn't emit nonsense? With the right math could we have been running LLMs in the 1990s?
- Good call. Right now though traffic is low (1 req per min). With the speed of completion I should be able to handle ~100x that, but if the ngrok link doesn't work defo use the google colab link.
- The link didn't work for me personally, but that may be a bandwidth issue with me fighting for a connection in the EU
- Thanks. Did you need to use Prism's llama.cpp fork to run this?
- Yep.
- Could you elaborate on what you did to get it working? I built it from source, but couldn't get it (the 4B model) to produce coherent English.
Sample output below (the model's response to "hi" in the forked llama-cli):
X ( Altern as the from (.. Each. ( the or,./, and, can the Altern for few the as ( (. . ( the You theb,’s, Switch, You entire as other, You can the similar is the, can the You other on, and. Altern. . That, on, and similar, and, similar,, and, or in
- I have older M1 air with 8GB, but still getting ober 23 t/s on 4B model.. and the quality of outputs is on par with top models of similar size.
1. Clone their forked repo: `git clone https://github.com/PrismML-Eng/llama.cpp.git`
2. Then (assuming you already have xcode build tools installed):
3. Finally, run it with (you can adjust arguments):cd llama.cpp cmake -B build -DGGML_METAL=ON cmake --build build --config Release -j$(sysctl -n hw.logicalcpu)
Model was first downloaded from: https://huggingface.co/prism-ml/Bonsai-8B-gguf/tree/main./build/bin/llama-server -m ~/Downloads/Bonsai-8B.gguf --port 80 --host 0.0.0.0 --ctx-size 0 --parallel 4 --flash-attn on --no-perf --log-colors on --api-key some_api_key_string- To the author: why is this taking 4.56GB ? I was expecting this to be under 1GB for 4B model. https://ibb.co/CprTGZ1c
And this is when Im serving zero prompts.. just loaded the model (using llama-server).
- I did this: https://image.non.io/2093de83-97f6-43e1-a95e-3667b6d89b3f.we...
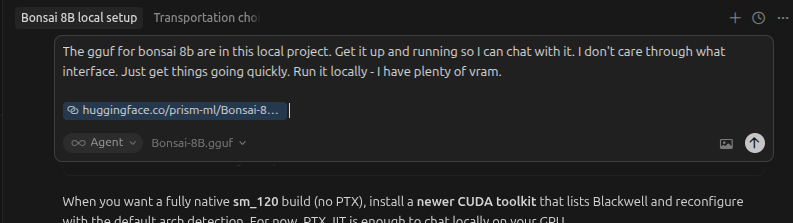
Literally just downloaded the model into a folder, opened cursor in that folder, and told it to get it running.
Prompt: The gguf for bonsai 8b are in this local project. Get it up and running so I can chat with it. I don't care through what interface. Just get things going quickly. Run it locally - I have plenty of vram. https://huggingface.co/prism-ml/Bonsai-8B-gguf/tree/main
I had to ask it to increase the context window size to 64k, but other than that it got it running just fine. After that I just told ngrok the port I was serving it on and voila.
- I reminds me of very early ChatGPT with mostly correct answers but some nonsense. Given its speed, it might be interesting to run it through a 'thinking' phase where it double checks its answers and/or use search grounding which would make it significantly more useful.
- The speed is impressive, I wish it could be setup for similar to speculative decoding
- man, that is really really quick. What is your desktop setup??? GPU?
- It is fast, but I do have good hardware. A few people have asked for my local inference build, so I have an existing guide that mirrors my setup: https://non.io/Local-inference-build
- thanks, i tested it, failed in strawberry test. qwen 3.5 0.8B with similar size passes it and is far more usable.
- I hope you are kidding, how is that a test of any capabilities? it's a miracle that any model can learn strawberry because it cannot see the actual characters and ALSO, it's likely misspelled a lot in the corpus. I've been playing with this model and I'm pleasantly surprised, it certainly knows a lot, quite a lot for 1.1G
- Interesting. Qwen 3.5 0.8B failed the test for me.
- wow that was cooler than I expected, curious to embed this for some lightweight semantic workflows now
- [dead]
- I ran my custom agentic SQL debugging benchmark against it and I'm impressed.
Results: 8 passed, 0 failed, 17 errored out of 25
That puts it right between Qwen3.5-4B (7/25) and Nanbeige4.1-3B (9/25) for example, but it took only 200 seconds for the whole test. Qwen3.5 took 976 seconds and Nanbeige over 2000 (although both of these were on my 1070 so not quite the same hardware)
Granite 7B 4bit does the test in 199 seconds but only gets 4/25 correct.
See https://sql-benchmark.nicklothian.com/#all-data (click on the cells for the trace of each question)
Errors are bad tool calls (vs failures which is incorrect SQL)
I used @freakynit's runpod (thanks!)
- I have been using @freakynit's runpod as well all be it, I like making working pomodoro apps as my own custom test, and although its not good for it (none of the prototypes work), I feel like it can be good within a specific context like Sql as you mention.
I imagine this being used as sub-agents with some sota models directing them but I wasn't really able to replicate it personally (I had asked Claude to create a detailed plan for a pomodoro app and then passed it to Bonsai)
I also tried its writing skills and actually they are kind-of decent, I also found that this model actually uses very comparatively little em-dashes.Its fine tunes are gonna be some really amazing things to come out. I hope someone makes a fine tune for website/tampermonkey extensions ;)
I remember using chatgpt-3 to use svelte/sveltekit to make a green button to blue button and having the text inside those buttons change and it's my personal wow moment from gpt-3 (This wasn't really able to accurately replicate it even in plain js), but I think that maybe the current model isn't good at writing html but the possibilities with custom-training these models and the idea of 1 bit model feels really great to me.
Especially with the idea of Ngram-embedding[0] (Meituanlongcat/LongCatFlashLite) and its idea. I imagine a 1 bit model + Ngram-embedding idea and I feel it can have many endless possibilities.
[0]: https://news.ycombinator.com/item?id=46803687 (I had submitted this but it seems to have had no attention during that time)
Maybe a 1 bit model like this and diffusion models for coding purposes might also go hand in hand, there are many experiments which can be done with this! (Also yes, many thanks to @freakynit running the runpod, I think I really learnt many things about this model in particular because of his runpod)
TLDR: I feel like this model is good within writing or atleast better in it than usual and it can be good asking it General purpose questions default but I feel like its not good at making html which can be fair, good to see that they are good in sql, but, not sure how they might approach in normal coding tasks. But either way, its an extremely fun model to play with!
(Edit: After some more tries, I have been able to make even one prototype of it after Gemini had holded its hands/giving it the code/errors, its not the best at this but still it works, just barely, https://gist.github.com/SerJaimeLannister/e90e8a134e4163f205...)
- > I feel like it can be good within a specific context like Sql as you mention.
Yes I think very constrained task: known data universe, well known language etc should be the best possible place for small language models to play
- Yes, I think though that, maybe 1) this shows 1-bit llm models working so more companies can do that so that we can get more competition within this space (+ ngram-embedding idea)
Another point, but I feel like, we can see some really good fine tuned models out of this model, the community feels excited about 1-bit LLM architecture. We are gonna see some good innovation within this space in the upcoming future.
- You can run this model on an iPhone via the latest update to this Locally AI app: https://apps.apple.com/us/app/locally-ai-local-ai-chat/id674...
For its size (1.2GB download) it's very impressive.
Here's a pelican it drew me running on my phone - the SVG comments are good, the image not so much: https://tools.simonwillison.net/svg-render#%3Csvg%20width%3D...
- One thing I discovered tonight is that it appears smaller models are remarkably bad at converting time between timezones.
I tested the following using almost all available models on Locally and did not get a single model that got the right answer.
"What is 9:30 am (Taiwan Standard Time, TST) in US Pacific?"
Did you ask for a pelican with a bicycle, or was that just an added bonus?<!-- Bicycle wheels --> <circle cx="285" cy="130" r="5" fill="#81c784" /> <circle cx="315" cy="130" r="5" fill="#81c784" /> <circle cx="285" cy="160" r="5" fill="#81c784" /> <circle cx="315" cy="160" r="5" fill="#81c784" />- The prompt I always use for this is:
Generate an SVG of a pelican riding a bicycle - It's a well known LLM test. Google "SVG pelican bicycle".
- The 1.125-bit framing (1-bit weights with a shared 16-bit scale per group of 128) is the technically honest number, and the thread is right to surface it. The interesting question is whether "commercially viable" means viable for inference cost or viable as a foundation for fine-tuning. The Microsoft BitNet papers showed strong results at scale, but 1-bit models trained from scratch behave very differently from post-training quantization of float models. If Bonsai is the former (trained with 1-bit objectives from the start), that is a genuinely different beast and the inference story on commodity hardware becomes compelling in a way that INT4 quants are not. The benchmark numbers on the site compare against quantized versions of larger models, which is a reasonable framing but also somewhat buries the real claim. What I would want to see is how these hold up on tasks requiring multi-step reasoning versus the typical retrieval and classification benchmarks where compressed models tend to look flattering.
- Think the commercially viable comment is a reference to the license not technical characteristics
- llm/bot comment
- Open access for next 5 hours (8GiB model, running on RTX 3090) or until server crashes or the this spot instance gets taken away :) =>
https://ofo1j9j6qh20a8-80.proxy.runpod.net
The server can serve 5 parallel request, with each request capped at around `13K` tokens..../build/bin/llama-server \ -m ../Bonsai-8B.gguf \ -ngl 999 \ --flash-attn on \ --host 0.0.0.0 \ --port 80 \ --ctx-size 65500 \ --batch-size 512 \ --ubatch-size 512 \ --parallel 5 \ --cont-batching \ --threads 8 \ --threads-batch 8 \ --cache-type-k q4_0 \ --cache-type-v q4_0 \ --log-colors onA bit of of benchmarks I did:
1. Input: 700 tokens, ttfs: ~0 second, outputs: 1822 tokens ~190t/s
1. Input: 6400+ tokens, ttfs: ~2 second, outputs: 2012 tokens at ~135t/s
Vram usage was consistently at ~4GiB.
- I genuinely love talking to these models
https://ofo1j9j6qh20a8-80.proxy.runpod.net/#/chat/5554e479-0...
I'm contemplating whether I should drive or walk to the car wash (I just thought of that one HN post) and this is what it said after a few back-and-forths:
- Drive to the car (5 minutes), then park and wash.
- If you have a car wash nearby, you can walk there (2 minutes) and do the washing before driving to your car.
- If you're in a car wash location, drive to it and wash there.
Technically the last point was fine, but I like the creativity.
- Update: this has been evicted by runpod as it was on spot.
- Thank you! I am impressed by the speed of it.
- That was really impressive. https://pastebin.com/PmJmTLJN pretty much instantly. (Very weak models can't do this.)
- Kind sir, May I say to you thanks for doing so! I really appreciate it :D
- [dead]
- Don't have a GPU so tried the CPU option and got 0.6t/s on my old 2018 laptop using their llama.cpp fork.
Then found out they didn't implement AVX2 for their Q1_0_g128 CPU kernel. Added that and getting ~12t/s which isn't shabby for this old machine.
Cool model.
- Are you getting anything besides gibberish out of it? I tried their recommended commandline and it's dog slow even though I built their llama.cpp fork with AVX2 enabled. This is what I get:
EDIT: It runs fine in their collab notebook. Looking at that you have to do: git checkout prism (in the llama.cpp repo) before you build. That's a missing instruction if you're going straight to their fork of llama.cpp. Works fine now.$ ./build/bin/llama-cli -hf prism-ml/Bonsai-8B-gguf -p "Explain quantum computing in simple terms." -n 256 --temp 0.5 --top-p 0.85 --top-k 20 -ngl 99 > Explain quantum computing in simple terms. \( , None ( no for the. (,./. all.2... the ..... by/
- I expect the trend of large machine learning models to go towards bits rather than operating on floats. There's a lot of inefficiency in floats because typically they're something like normally distributed, which makes the storage and computation with weights inefficient when most values are clustered in a small range. The foundation of neural networks may be rooted in real valued functions, which are simulated with floats, but float operations are just bitwise operations underneath. The only issue is that GPUs operate on floats and standard ML theory works over real numbers.
- Inference at low bit-widths is easy. Training is where the wheels come off, because you spend the saved math budget on gradient tricks and rescaling just to stop the model from drifting.
That trade loses outside tight edge deploymints. Float formats stuck around for boring reasons: they handle ugly value ranges and they fit the GPU stack people already own.
- Well this is perfect then. We just post-process models like this after training.
- > and standard ML theory works over real numbers.
This paper uses binary numbers only, even for training, with a solid theoretical foundation: https://proceedings.neurips.cc/paper_files/paper/2024/file/7...
TL;DR: They invent a concept called "Boolean variation" which is the binary analog to the Newton/Leibniz derivative. They are then able to do backpropagation directly in binary.
- I’m really curious how this scales up. Bonsai delivers an 8B model in 1.15 GB. How large would a 27B or 35B model be? Would it still retain the accuracy of those large models? If the scaling holds, we could see 100+B models in 64 GB of RAM.
- Also depends on how expensive training these models is. It's probably at least as expensive as full precision models, otherwise they would have mentioned it.
- My guess is the training process is their secret sauce...
- Yes, but their training speed is not secret. If their process were fast, they would have said so.
- [dead]
- The 8B model response to my "Harry Potter knowledge-bench" question is too funny not to share.
> *Fathers of Harry and James Potter*: - Sirius Black is the *father* of *James Potter* (the older brother of Harry).
> - James Potter is *Harry's uncle* and the *older brother* of *Luna Lovegood*.
> - This means *Sirius and James are Harry's uncles*, though they are *father and brother*.
- I'm very skeptical of the advantage they're claiming here. The whitepaper [0] only compares these to full precision models, when the more interesting (and probably more meaningful) comparison would be with other quantized models with a similar memory footprint.
Especially considering that these models seem to more or less just be quantized variants of Qwen3 with custom kernels and other inference optimizations (?) rather than fine tuned or trained from scratch with a new architecture, I am very surprised (or suspicious rather) that they didn't do the obvious comparison with a quantized Qwen3.
Their (to my knowledge) new measure/definition of intelligence seems reasonable, but introducing something like this without thorough benchmarking + model comparison is even more of a red flag to me.
[0] https://github.com/PrismML-Eng/Bonsai-demo/blob/main/1-bit-b...
- Actually IMHO the promise would be beyond standard FP4 quants. I think the goal is more where 1.58 bit (ternary) quants are heading. Having said that it would be interesting to see performance on nonstandard HW.
- Interesting parallel to spiking neural networks — they're essentially 1-bit communication (spike or no spike) with analog membrane potentials. We use 5k Izhikevich neurons for quadruped locomotion control and they beat PPO at the same sample budget. The efficiency argument for 1-bit goes beyond LLMs.
- What’s the trade-off? If it’s smaller, faster and more efficient - is it worse performance? A layman here, curious to know.
- Their own (presumably cherry picked) benchmarks put their models near the 'middle of the market' models (llama3 3b, qwen3 1.7b), not competing with claude, chatgtp, or gemini. These are not models you'd want to directly interact with. but these models can be very useful for things like classification or simple summarization or translation tasks.
These models quite impressive for their size: even an older raspberry pi would be able to handle these.
There's still a lots of use for this kind of model
- [dead]
- If you look at their whitepaper (https://github.com/PrismML-Eng/Bonsai-demo/blob/main/1-bit-b...) you'll notice that it does have some tradeoffs due to model intelligence being reduced (page 10)
The average of MMLU Redux,MuSR,GSM8K,Human Eval+,IFEval,BFCLv3 for this model is 70.5 compared to 79.3 for Qwen3, that being said the model is also having a 16x smaller size and is 6x faster on a 4090....so it is a tradeoff that is pretty respectable
I'd be interested in fine tuning code here personally
- What's up with - log error / model size? I'm not an LLM person, but a ratio of ~1 means a roughly 40% error rate for its size? I don't follow
(math: - log error / model size = 1 <-> error / model size = 1/e )
- Feels a bit like gradually moving back toward analog circuits, step by step. There is less and less need for the precision that digital circuits provide.
- What ? How did you come to this conclusion with this context ?
- Traditional programming requires the absolute precision provided by digital circuits; a single bit flip can lead to a completely different outcome.
Large models do not require that kind of exactness. They are somewhat like a "field" or a "probability cloud": as long as the main directional tendency is correct, a few individual deviations—or even a whole cluster of them—make almost no difference.
- A bit misleading to say they take 14x less memory, no one is doing inference with 16-bit models.
- Oh, boy. This good tool hates my LM Studio... The following message appears when I run Bonsai in my LM Studio. I think my settings have done something wrong. ``` Failed to load the model Error loading model. (Exit code: null). Please check the settings and try loading the model again. ```
- Same issue here, wanted to give it a shot but ran into that error trying to load the model in lm studio.
- Does anyone know how to run this on CPU?
Do I need to build their llama.cpp fork from source?
Looks like they only offer CUDA options in the release page, which I think might support CPU mode but refuses to even run without CUDA installed. Seems a bit odd to me, I thought the whole point was supporting low end devices!
Edit: 30 minutes of C++ compile time later, I got it running. Although it uses 7GB of RAM then hangs at Loading model. I thought this thing was less memory hungry than 4 bit quants?
Edit 2: Got the 4B version running, but at 0.1 tok/s and the output seemed to be nonsensical. For comparison I can run, on the same machine, qwen 3.5 4B model (at 4 bit quant) correctly and about 50x faster.
- Sounds like about the right level of cognition for a talkie toaster!
- Interesting post. Curious to know how they arrived at intelligence density = Negative log of the model's error rate divided by the model size.
- What is model's error rate?
- i hope someone do a 100b 1-bit parameter model. that should fit into most 16GB graphics cards. local AI democratized.
- The site says 14x less memory usage. I'm a bit confused about that situation. The model file is indeed very small, but on my machine it used roughly the same RAM as 4 bit quants (on CPU).
Though I couldn't get actual English output from it, so maybe something went wrong while running it.
- Super interesting, building their llama cpp fork on my Jetson Orin Nano to test this out.
- Tried running the models with the latest LM Studio, llama.cpp, and Ollama. All failed.
https://huggingface.co/prism-ml/Bonsai-8B-gguf
tensor 'token_embd.weight' has invalid ggml type 41. should be in [0, 41) loader knows tensor types 0..40, but the model contains type 41
- prismML provides a llama.cpp fork which is compatible with the 1 bit models:
https://github.com/PrismML-Eng/llama.cpp
After fails with Ollama and main llama.cpp the fork worked on my M5 MBA.
Edit: Typos
- I can’t see how this is possible. You’re losing so much information.
- It's because they're natively trained with 1 bit, so it's not losing anything. Now, the question might be how they manage to get decent predictive performance with such little precision. That I don't know.
- Not training. Transposing rows/columns of matrices to group 128 parameters with similar (shared) scale factor. Qwen-3 model.
- I'm not sure what you mean. Could you please elaborate?
- I always remind myself and everyone else that human DNA is "only" 1.6 GB of data, and yet it encodes all of the complex systems of the human body including the brain, and can replicate itself. Our intuitive feel of how much stuff can be packed into how many bits are probably way off from the true limits of physics.
- That's not strictly true - DNA doesnt replicate itself, a cell with DNA replicates itself.
You need to count the information contained in the non-DNA part of the cell too.
Just in case it's not obvious, you can't take human DNA and put it in a cat cell, it won't work, that cell won't replicate.
- True.
For now, the DNA replication and the synthesis of RNA and proteins using the information stored in DNA are the best understood parts about how a cell grows and divides, but how other complex cellular structures, e.g. membranes or non-ribosomal peptides, are assembled and replicated is much less understood.
We need more years of research, perhaps up to a decade or two, until we will be able to know the entire amount of information describing a simple bacterial cell, and perhaps more than that for a much more complex eukaryotic cell.
- It encodes the data on top of locally optimal trajectories in the physical world that were learned in millions of years of evolution. Treat this as context, not weights.
- Human DNA has 3.2 billion base pairs, and with 2x the information density compared to binary systems (due to 4-letters as opposed 2), that's roughly 800MB of informational data.
Second, what's even more crazy is that roughly 98% of that DNA is actually non-coding.. just junk.
So, we are talking about encoding entirety of the logic to construct a human body in just around 16MB of data!!!
That's some crazy levels of recursive compression.. maybe it's embedding "varying" parsing logic, mixed with data, along the chain.
- >Second, what's even more crazy is that roughly 98% of that DNA is actually non-coding.. just junk.
I think it's a myth that non-coding DNA is junk. Say:
https://www.nature.com/articles/444130a
>'Non-coding' DNA may organize brain cell connections.
- As another poster has said, much of the "junk" is not junk.
The parts of the DNA with known functions encode either proteins or RNA molecules, being templates for their synthesis.
The parts with unknown functions include some amount of true junk caused by various historical accidents that have been replicated continuously until now, but they also include a lot of DNA that seems to have a role in controlling how the protein or RNA genes are expressed (i.e. turning off or on the synthesis of specific proteins or RNAs), by mechanisms not well understood yet.
- And anybody who’s ever met a baby can tell you, they score very poorly on most llm benchmarks.
- Eagerly waiting for mlx to merge 1bit quantization pr to try this out.
- How much does training such a model cost?
- Misses comparison with qwen 3.5, though mentioned qwen 3. Is there a reason why?
- Extremely cool!
Can't wait to give it a spin with ollama, if ollama could list it as a model that would be helpful.
- Very cool and works pretty well!
- I'm fascinated by these smaller models.
The amount of progress they've been making is incredible.
Is anyone following this space more closely? Is anyone predicting performance at certain parameter sizes will plateau soon?
Unlike the frontier models, these don't seem to be showing much progress of slowing down.
- On the harness side there's a huge amount of optimisation room to go as well.
I strongly think smaller models will end up being able to do most coding tasks in the future, once they are reigned in properly
- really impressive for the size. Curious to see what happens when someone trains a 100B+ model natively at 1-bit.
- Is Bonsai 1 Bit or 1.58 Bit?
- 1-bit g128 with a shared 16-bit scale for every group. So, effectively 1.125 bit.
- I was excited about the 1.58 bit models from a year or two ago, but the never seemed to go anywhere. Curious in particular how this scales up.
- 1 bit or 1 trit*
- Great! I hope the era of 1-bit LLMs really gets going.
- any tutorial on how to run this on linux cpu only?
- This looks very promising. It would be cool if support for Bonsai-style models would land in mainline MLX soon, looking forward to trying it out.
It seems PrismML has implemented a better version of an idea I had a while back: what if we had a 1-bit model where the scale of the weight is determined by its position. The model would have to be trained from the ground up for this though, which is why I never tried it. The interleaved scale factor approach of Bonsai is a much more flexible approach at almost the same cost.
- What is the value of a 1 bit? For those that do not kno
- That you can process many operations with a single instruction.
- I can port it to an FPGA and so can you.
- Speed and density.
- "Now do ~2-bit and ~4-bit"
Srsly though.
- Ran this prompt: Share an interesting scientific discovery or historical fact that most people don't know about. Please explain why it's significant and its impact on our understanding.
Got this nonsense answer: Interesting Scientific Discovery: The Discovery of the "Boson" in 1924 by Charles K. Alton ("Chuck") Alton
What it is: In 1924, American physicist Charles K. Alton discovered the "boson", a particle that would later be named after the Italian physicist Enrico Fermi. This discovery was made while he was working at the University of Chicago, where he was studying the properties of neutrons and protons.
Why it's significant: The boson Alton discovered was the meson, a subatomic particle that plays a crucial role in the strong nuclear force that holds atomic nuclei together. However, Alton's original work was more focused on the neutron, and he mistakenly identified the boson as a neutron—a common mistake at the time. This was not a scientific error, but rather a misunderstanding of the data. His work, however, laid the groundwork for the later discovery of mesons by Enrico Fermi and Richard Feynman, which was a major breakthrough in the field of particle physics.
Impact on Understanding:
• Mesons are now known to be the carriers of the strong force, which is one of the four fundamental forces of nature. • This discovery helped physicists understand the structure of the nucleus and the nature of nuclear binding. • It was a key step in the development of quantum chromodynamics (QCD), which describes the strong force at the subatomic level. • Alton's work is often overlooked in the history of particle physics, yet it was a critical early step in the field.
Why it's interesting: This story highlights how even early scientific discoveries can be misinterpreted or overlooked—sometimes not because of a lack of intelligence, but due to the complexity of the data and the evolving nature of scientific understanding. It also shows how one scientist's work can be built upon by others, leading to major breakthroughs.
Bonus: Alton was not the only person involved. His work was built upon earlier research by Edward Teller and Leopold Rabi, and it was ultimately Fermi who discovered the meson in 1932 using the "storm cloud" method, where he used a cloud chamber to observe the effects of high-energy particles.
So, while the boson Alton discovered was initially misidentified, it was a crucial piece of the puzzle in the development of modern particle physics.
- Either we will be expecting the models to compress whole wikipedia and stale on the size reduction, or focus on the reasoning capabilities. My intuition is that by forcing models to remember everything we are wasting parameter space which can be allocated for more abstract thinking.
- Integrating tool use into the training process should fix this.
Rather than learn about President Lincoln, the model can learn to look that info up with a search tool and use it to get better answers.
Just like a human does. I don't learn what 76x35 is... I learn that a calculator can give me that answer so I don't need to memorize it.
- Really funny how it multiplexes together in a quasi-random order very short excerpts from the true descriptions of various discoveries made by Bose, Einstein, Fermi, Dirac, Yukawa and a few others into a completely nonsense text.
- [dead]
- It's been a hell of a morning for llama heads - first this, then the claude drop and turboquant.
I'm currently setting this one up, if it works well with a custom LoRa ontop ill be able to run two at once for my custom memory management system :D
- [dead]
- [dead]
- [dead]
- [dead]
- [dead]
- [dead]
- [dead]
- [dead]
- [dead]
- [dead]
- [flagged]
- [flagged]
- "Don't post generated comments or AI-edited comments. HN is for conversation between humans."
- How can you tell?
- Presumably because a new account, and an offtopic post about AI. Then you look at the post history.
- I feel like it's a little disingenuous to compare against full-precision models. Anyone concerned about model size and memory usage is surely already using at least an 8 bit quantization.
Their main contribution seems to be hyperparameter tuning, and they don't compare against other quantization techniques of any sort.
386 points by PrismML 23 hours ago | 145 comments
{kind=link}